Zero-Trust: An Alternative to Perimeter Defense
Based on Zero Trust Networks by Evan Gilman and Doug Barth
Here's the scenario: you are deploying a simple network, with only a few local machines that can connect to the Internet through your router. You want these machines to communicate locally with one another, and to websites located on external networks, but you don't want connections to be established from outside the network. You, a capable sys admin, deploy a firewall between the local network and the Internet to protect your network. All is well, and your network seems to be secure.
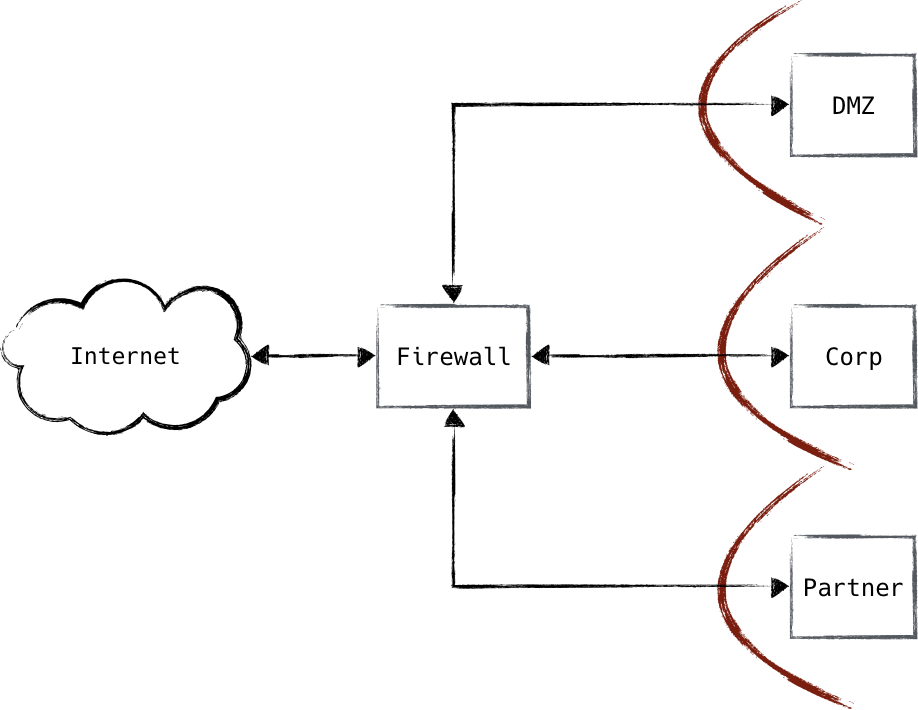
Now you need to deploy a web server on your network that is accesible from beyond your router. Now you change settings in your firewall that allow external connections to a server on your network on port 80. The first hole of many in your defenses.
You continue expanding your network, setting up more public resources, adding in VPN's, and creating more openings for malicious traffic to enter your network. Your firewall is beginning to look more like fishing net, capable of stopping larger and more obvious attacks, but with enough gaps to give opportunities to allow something through.
This is the perimeter defense approach to protecting networks. With this security scheme, all attacks are hopefully stopped at the firewall. But what happens if an attacker makes it through? What happens if an attack is an insider in your network? A traditional firewall does not defend against these scenarios, but can only alert after the damage is already done.
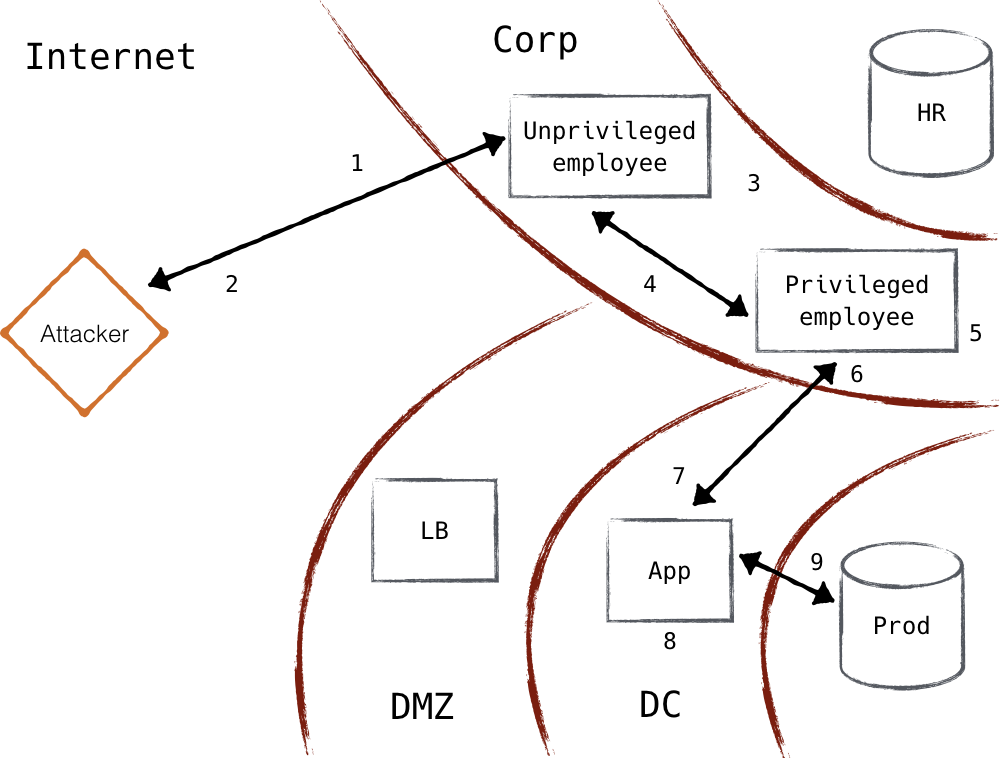
In the figure below, an attacker compromises a network through a phishing email, and is able to escalate privileges to access a resource that should be unavailable. The firewall is easily bypassed and by compromising specific machines to get root provileges, the attacker has full reign in the network.
Enter the zero trust framework. This scheme for designing and maintaining networks assumes that ALL network traffic is malicious or untrusted until proven otherwise. If a packet cannot be authenticated and authorized, then it is dropped by the controller. Originally proposed by Forrester Research, Inc. to the National Institute of Science and Technology (NIST) in 2013, this concept builds on top of a software-defined network, and describes the protocols and schemes needed to verify and authorize all traffic within a network.
In a software-defined network, the network functions are split into two domains: the control plane and the data plane. The control plane is the software and managing functions that determines where traffic should switched or routed to. The data plane is the hardware functions of a switch that physically moves the packets from one location to another. On traditional switches, these functions are combined into one device. In a software-defined network, a sysadmin is able to use the control plane to manage the traffic flows from a family of switches, rather than needing to manage each switch individually. In an SDN, a switch forwards all traffic up to a controller for flow analysis, and then routes the data received from the controller to the appropriate source.
A zero trust network utilizes this controller to operate the authorization and authentication of all traffic. If the controller cannot verify the trustworthiness of the traffic, the packet is simply dropped. Trust is calculated using three different types of authentication: device, user, and application authentication. In many situations, specifically in automated software, the user and the application are the same entity.
Trusting Devices
There are a few ways to calculate a level of trust for a specific device, the first of which is the time since image . The longer a device has been in use, the more likely it is to have been tampered with.
A controller can calculate a level of trust based on the history of access for a particular device. An old device that has not authenticated in a long time may be met with skepticism if it attempts to access a newer resource. Frequency of operation can also be used to calculate trust, as a device making an abormal number of requests could be compromised.
While a rather difficult piece to observer, the location of a device can be used to gather some information about trustworthiness. With IP spoofing being rather simple for most attackers, this concept is not to be leaned on as the only way of calculating trust. In some situations, location can help. For example, a device is authenticated once in the United States, and then the same device certificate is used in Europe.
Trusting Users
Trusting a user is a difficult task. When sitting across the table from someone, you can know with some certainty that they are who they say they are. However, it is difficult to know if someone on the other side of a computer is who they say they are. This is why it is especially important, not just in a zero trust model but in general, to protect any information that could be used to authenticate you as a user, whether that is a password, U2F token, or cell phone.
In a zero trust model, a user identity is built around a number of characteristics of the user. This can range from simply name and phone number to things as complex as current location and the details of the security certificate they are using to authenticate into the network. The identity of the user and the method they use to authenticate will give a certain level of trust for a particular resource. If a user is not trusted enough to access a resource due to their identity, they may be prompted to provide more information to verify their identity to ensure they have authorization and trust to access that resource.
Signals of trust for a user are similar to a device, as a user is often tied to a number of devices. Location, access history, and frequency of use can be indicators of whether a particular user can be trusted to access a resource.
Trusting Applications
Trusting applications can be rather difficult, due to the many steps taken in their development and deployment. Version control systems help hold developers accountable and can be used to manage access to software in development. Compiling software on a trusted device helps improve trust for the software. In the build process, all configurations and build tools should be protected to prevent any outside interference in the process.
By using reproducible builds , multiple users can compile the same code on different machines produce the same output. This is helpful in verifying that the build process was not tampered with, as any build that is not like the others was likely interfered with and should not be trusted.
Trust Calculation
Using multiple avenues of gathering trust, a score is calculated. It is up to the managers of the network to determine which signals of trust have more of an impact on the score. The score then determines whether the user/application that is authenticating has permission to access a particular resource. In some cases, a user/application may not have access to a resource, even if it is trusted enough. This is similar to a standard perimeter defense model with different security zones, in that different groups have access to different groups of resources.
The trust score is calculated at the controller, which contacts the different databases and services to verify the validity of certificates, locations, or passwords. If the controller allows the connection, it returns the packets to the switch with a command to pass the packets along to its destination. Otherwise, the controller simply drops the packet and disallows the connection.Issues and Future Work
Zero trust is not a new concept, as it was initially proposed over 4 years ago. Many large corporations, including Google , have implemented zero trust networks into their infrastructures. This means that many issues with zero trust have been recognized and dealt with. One of the initial issues that could be recognized with a zero trust network is the use of a single controller. This produces a single point of failure where a simple DDoS attack would disrupt an entire network. However, the use of distributed computing and multiple nodes for this controller mitigates the damage done by any attempts to disrupt availability.
With some research, there was little found on the feasibility of producing small-scale zero trust networks. For smaller businesses or even home networks, it would be difficult to manage security certificates for the devices connecting to a network, especially with the use of WiFi. An exploration into the ways of deploying a zero trust model into small networks would be worthwhile.
Another field of exploration would be to look at how the controller calculates the trust score. Determining which signs are the most viable best indicators of trust would help sysadmins focus their time on securing a particular signal, such as device history of access.