Modern fuzzing technologies
Fuzzing is a technology used in nowadays to find interesting crash inside an application. An interesting crash potentially will potentially be a dangerous bug. The general idea of fuzzing is make some test cases as input, and then feed these test cases into the binary program being tested. If the program generate a unique crash then the fuzzer record it. If not, the fuzzer mutate the test cases according to some information. This information can be feed back from the instrumented binary program. This blog discuss about the underlying technology of three modern fuzzing technologies, AFL, Driller and VUzzer. I will first introduce the high level ideas of these three fuzzers following with their strength and drawbacks. Every intro will come with experiments as example. At the end, I will discuss what we can do in the future.
Part I: American Fuzzy Lop (2013 to current)
Design Goal:
1. AFL targets for speed, so it wants minimum instrumentation and has a lot of data structure optimization, for example its state transition table is 64kb and can be put into the L2 cache.
2. AFL targets for reliability, so it wants to be able to fuzz real world applications.
3. AFL targets for simplicity, so it only need the user to play with output file, memory limit, and ability to override default. The other settings are supposed to just work.
4. AFL targets for chainability, so it can allow user to create small corpora of interesting test cases that can be fed into manual testing process. (this won't be mentioned in this blog)
How AFL actually works:
The high-level idea of AFL is genetic input generation according to state transition and basic block transition hit frequency count fitness score generated by light-weight instrumentation. AFL will follow up more on the test cases with new behaviors.
Let's explain the concepts in the former sentenses. Genetic input means the initial inputs or test cases are used as seeds to generate following test cases. The ways can be mutation or subsititution and that is similar to gene, so that is where the name genetic alogrithm comes from. The next concept is state transition. We know for every binary, when you dissamble them, they are simply a lot of basic blocks, so we say every basic block is a state. And let's give every basic block an ID. State transition means a tuple (A,B) where A and B are two basic blocks. After that, what is basic block hit frequency count? It is literally the number of occurrance of basic blocks state transition. Both of the above two features can mean a new behavior. Fitness score is basically a cost function, which means how much we value the former two behaviors. Light-weight instrumentation means we patch the original binary application with some assembly code which helps generate features within each execution. The last concept, new behaviors include a new state transition tuple or a increase of hit frequency.
So how does AFL achieve those high level ideas? Let's take a look at the implementation or instrumentation.
AFL add three lines of code to end of every branch in the binary application being tested. The psuedo code for the three lines of code is as following:
1. cur_location = <COMPILE_TIME_RANDOM>;
2. shared_mem[cur_location ^ prev_location]++;
3. pre_location = cur_location >> 1;
Line 1 determines the ID of the basic block. And line 2 is to assist calculating the hit frequency. Line 3 is for the state transition. What worth mention here, remember when we talked about new behaviors, there are two situations. One is new state transition tuple, and the other is frequency count. The bucket for frequency count is 1,2,3,4-7,8-15,16-31,32-127,128+. Only the transition between these buckets will count as a new behavior.
The injected assembly code for 64bit/32bit can be found in afl-as.h file. We can modify this if we want to add more instrumentation. The instrumentation will record the information of execution of modified binary in shard memory. The afl-fuzz application will get the shared memory in modified binary by shmget() after the execution of it. And it use that information to mutate the input.
Eamples:
Now that we know how AFL works, let's look at some examples. We have a vulnerable code fuzzme.c as listed below:
#include <stdio.h>
#include <string.h>
int main( int argc, char *argv[] ) {
char buff[15];
gets(buff);
if( strcmp(buff, "12") == 0 ) {
char buff2[1];
gets(buff2);
printf("The input supplied is %s\n", buff);
}
else {
printf("Hello.\n");
}
}
With the test case being a file with a single character "1" in it, we can get the two crash cases within minutes. I have also added 3 other test case files which have some simple characters. The following figure is the interface when you invoke AFL:
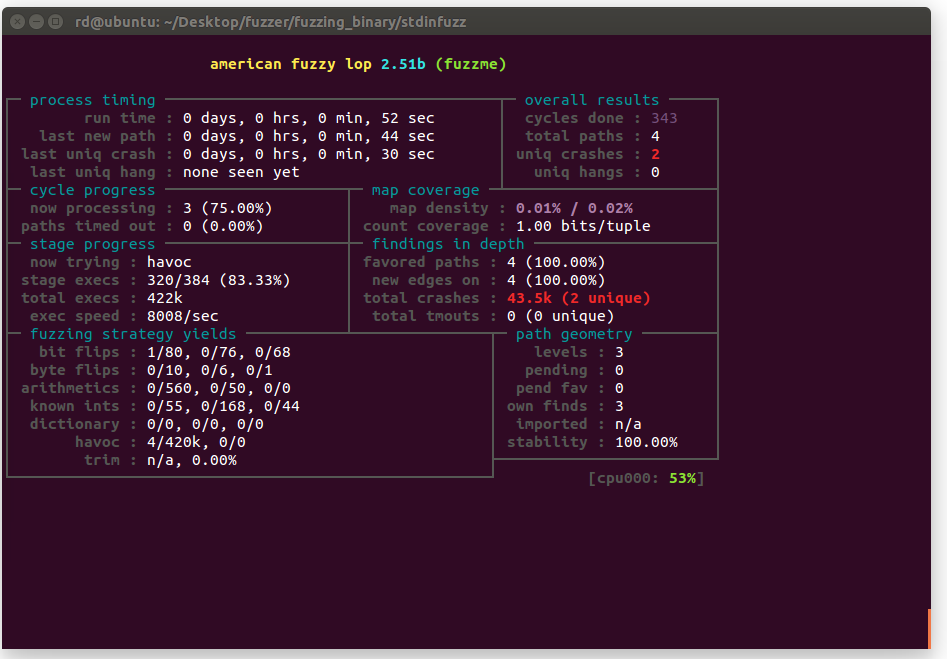
The crash report and cases are saved in results directory. As you can see in the figure, it finds the two strcpy buffer overflow crash.
For example, we change the fuzzme.c code to:
#include <stdio.h>
#include <string.h>
int main( int argc, char *argv[] ) {
char buff[15];
gets(buff);
if( strcmp(buff, "123456789") == 0 ) {
char buff2[1];
gets(buff2);
printf("The input supplied is %s\n", buff);
}
else {
printf("Hello.\n");
}
Part II: Driller (2016)
Design Goal:
Drill deeper to the code through solve the issue of complex magic number check.
On high level, driller use the concept of compartments (e.g. cp | /home/rd/ | /home/ ), it use AFL to explore the values within the general part of each compartment and use conclic execution to find specific values to a compartment (e.g. a special complex check). It use AFL first, and when AFL fails to find any more interesting unique crash after a time threshhold, it use driller to find more interesting input for every crash AFL found. After another time threshold when driller stuck, it calls AFL again, and rotating between these two parts.
In detail, the AFL will generate unique crashes and intereting inputs of the binary application in two different folders, and after some time when the AFL cannot explore any more paths, driller is triggered. Driller will take interesting inputs and run the application with those inputs. While running, driller will trace each input symbolically and mutate them to discover more paths. Interesting inputs satisfy two conditions: 1. The path, that the input causes the application to take, was the first to trigger some state transition. 2. The path, that the input causes the application to take, was the first to be placed into a unique "loop bucket". (a carefull reader can find this is exactly what AFL use to determine which are interesting inputs). Driller will identify state transitions AFL was unable to satisfy and use concolic execution engine to produce input that would drive execution through this state transition.
The way driller drive execution through state transition is by the following way. After the traces are passed to symbolic execution, everytime when Driller meet a conditional control flow transfer, it checks if inverting that condition would result in the discovery of a new state transition. If it will, driller generate an example input and pass it to the input queue of AFL. What worth mentioning here is that during the generation of input, Driller will record the path constraints following the path to make sure the input will follow the previous route.
int __attribute__((fastcall)) main(int unimportant, char *unused[]) {
char buf[1024];
int ret;
size_t size;
while (1) {
size = receive_line(STDIN, buf, sizeof(buf) - 1);
if (size == 0)
_terminate(1);
buf[size] = 0;
if (buf[0] == 0x41 && buf[1] == 0x42 && buf[2] == 0x61 && buf[3] == 0x66 && buf[4] == 0x67 && buf[5] == 0x44 && buf[6] == 0x42 && buf[6] == 0x42 \
&& buf[7] == 0x46 && buf[8] == 0x51 && buf[9] == 0x55) {
char *p = 0;
p[0] = 10;
}
ret = transmit_all(STDOUT, buf, size);
if (ret != 0)
_terminate(1);
}
}
Basically, it receive a input from commandline and echo it, if the input prefix is as in the buf, the program crash. Most of the crash is under the if branch, transmit_all and receive_line function are not totally bugless. Let's fuzz it using AFL first and then Driller for comparison.
The command to run AFL on it is:
shellphuzz -i -c 1 ./RDTEST_00001
After running from 11:39AM to 12:13PM, AFL finds 2 unique crashes. From 12:13 to 14:28, it found 11 unique crashes. But still not the crash inside complex check.
Then we use command to trigger driller when AFL get stuck after 4min of running:
shellphuzz -i -c 1 -d 1 ./RDTEST_00001
After running from 14:31 PM to 13:31PM, it found 7 unique crashes. But the complex check is not found yet. After run till 17:11PM, still 7 unique crashes and i give up and decide to change the code to the following:
int __attribute__((fastcall)) main(int unimportant, char *unused[]) {
char buf[15];
int ret;
size_t size;
size = receive_line(STDIN, buf, sizeof(buf) - 1);
if (size == 0)
_terminate(1);
buf[size] = 0;
if (buf[0] == 0x41 && buf[1] == 0x42 && buf[2] == 0x61 && buf[3] == 0x66 && buf[4] == 0x67 && buf[5] == 0x44 && buf[6] == 0x42 \
&& buf[7] == 0x46 && buf[8] == 0x51 && buf[9] == 0x55) {
char *p = 0;
p[0] = 10;
}
ret = transmit_all(STDOUT, buf, size);
}
Driller found it at 5:19PM. so it only took less than 10 mins.
machine time: 1507497495 - 1507496900 = 595
AFL found it at
machine time: 1507499525 - 1507496890 = 2635
At the time stop runing at 18:10 PM. AFL found 4 hangs, compared to driller found 8 hangs.
Part III: Vuzzer (2017)
Design Goal:
1. Solve the issue of complex magic number check.
3. Solve nested if else statements. (unsolvable by driller, since AFL mutate the input randomly after driller gives AFL the input go beyond the first if else condition.) (solve by assign basic block weights.)
4. Consider the error handling blocks are not as interesting, so do not go along that path.
5. Solve the issue of Markers in the code (Markers are basically multibyte magic numbers in a random offset of the input. Mostly at the begining of the input file. e.g. 'ELF' in elf file)
On high level, first, vuzzer weights the basic blocks according to control flow so that vuzzer can pay more attention to deep blocks when mutate input. Second, vuzzer record cmp instructions to find the number the program is comparing the input with which is called using data flow.
In detail, vuzzer first use IDA pro to obtain imm values of cmp instructions by scanning the binary code, then it compute the weights for basic blocks of the binary. The imm values will be saved in a Limm list of byte sequences. Basic blocks weights are saved in Lbb list. The weights are determined by Markov model with the CFG of each function. Basically 1/prob, the prob is assumed to be equal for 2 branches of any basic block.
The next step is to set up 4 initial test seed cases and use DTA (dynamic taint analysis) to track the running of this four seeds. By doing this, vuzzer can get the magic byte and error-handling code. This finish the initialization for 1st generation of input. Then vuzzer execute program with each inputs in 1st generation and generate the corresponding execution traces of executed basic blocks (basic block tracking is by intel pin tool directly). If the execution trace contain unseen basic block, vuzzer taint that input and use DTA to infer its structural properties. After that, vuzzer calcuate fitness point of each input according to traces and assigned weights in Lbb. In the end, vuzzer generate the next generation of inputs based on combining and mutating inputs from seed inputs, tainted inputs, top n% of fitness point as root set. Vuzzer use crossover and mutation on root set with the help of Limm.
(DTA is used to monitor flow of tainted input (files, network packets, etc). DTA can determine during program execution, which memory locations and registers are dependent on tainted input. Based on granuality, DTA can trace back the tainted values to individual offsets in the input. So cmp op1, op2 will be tainted at byte level. And stored as cmpi = (oi, vi), o as offset, v as value, i means the number of cmp instruction.)
Error-handling code detection is based on valid inputs as assumption of Vuzzer. Vuzzer record the execution traces of valid inputs and then compared it with execution traces of random input. The union set is valid basic blocks, and others in execution traces of random input are error-handling code. Also, an incremental analysis is performed to further detect error-handling code. Basically, it is based on that majority of newly generated inputs will end up trggering some error-handling code. If 90% of inputs newly generated falls into that basic block, then that basic block is classified as error-handling basic block if it is not in the valid basic block set.
For implementaion detail, Vuzzer use IDA pro with a python script to infer the importance of each basic block and find constant strings. They assign higher weights for deep path basic blocks and low weight for error-handling code. This solves the design goal 3 and 4.
Vuzzer use intel pin tool to trace basic block dynamically along with its frequency and encountered during the execution. Vuzzer pin tool can selectively trace basic blocks executed by certain library on-demand to reduce the execution trace overhead and focus on intended application code.
Vuzzer modifies Datatracker which is based on LibDFT on top of pin tool to taint the input. Vuzzer reduce the tag structure for memory location to save time and memory. Vuzzer add instrumentation callbacks for cmp family and lea instruction to catch byte-level taint information. Vuzzer rewrote hooks in Datatracker for each implemented system call to evaluate vuzzer with DARPA dataset. This data-flow feature maps input data with cmp computations. And when the input with offset is compared with a immediate or register value using cmp family, vuzzer will record that and mutate input at those offset. This solves the design goal 1 and 5. Also, lea instruction (load effective address: load the memory address of a value) is monitored.
The static analysis using IDA pro is fast. Although, dynamic instrumentation using Pin tool add a lot of performance overhead, vuzzer use it as sparingly as possible. So the design goal 2 is acheived.
Examples,
After building the environment following https://github.com/vusec/vuzzer.
It turns out it can only fuzz the example binary application but not newly generated ones.
There has been an issue opened 22days before but no one replies.