Let’s say you are a good friend of Professor Xavier and you want to build an AI for him so he won’t suffer from using the gigantic Cerebro machine. Just like what Prof. X can do with Cerebro, your machine is expected to locate, recognize, and classify every mutants on the earth, and you are quite sure that some wily-and-naughty mutants like the Wolverine are trying to evade the detection of your machine. They may simply hide themselves to avoid brainwave scanning, disguise a human being by attaching more human features, or even “poison” your machine’s database by feed it with long-term fake data, just like what the Magneto’s legion would do.
Yes, I was talking about adversarial machine learning, for a fictional AI that would help in the X-Men comic series. So what is the exact meaning of adversarial machine learning?
Adversarial Machine Learning
Formally speaking, adversarial machine learning is the study of effective machine learning techniques in adversarial settings, typically against an adversarial opponent [6][7].
Since machine learning has become ubiquitous in most technological sectors of modern society, there are various adversarial settings to consider. To name a few, email spammers are sending complicate and byzantine contents to evade spam filters, hackers are trying new intrusion patterns to dodge network intrusion detectors, and some powerful attackers such as enterprise-level opponents and state-sponsored hacking groups can “poison” a targeted ML system by feeding it with nuanced and imperceptible malicious training samples. Additionally, as machine learning techniques has become an important tool for building secured systems, the adversary only knows too well that crushing the machine learning component is essential to its ultimate goal of bringing down the entire target system.
Attack Taxonomy
To categorize possible attacks against machine learning, [3] provides a taxonomy based on the three properties: influence, security violation, and specificity.

Figure 1. Three properties of an attack against machine learning
Causative attacks will cause changes in the target ML model, while exploratory attacks only seek to fool the ML detection system without altering them. Integrity attacks aim to lead the target system to classify an adversarial data point as benign (false negative). Availability attacks will eventually results in blocking the ML system from performing normal tasks. While privacy attacks focus on obtaining the ML system users’ private information. Targeted attacks are against a particular data point or class, while indiscriminate attacks will profit from any false negative.
To facilitate the understanding of these properties, the next section gives three attack examples from three research papers.
Three Attack Examples
Example 1: Evading Facial Recognition Systems [4]
A facial recognition system (FRS) is a device that identify the person to whom a given face image belongs. Previously the commonly used ML algorithm for FRS is Support Vector Machine (SVM), while in recent years systems based on Deep Neural Networks (DNN) became the state-of-the-art.
The adversary wishes to pass the FRS without triggering any suspicion. Sh/e can achieve it by either dodging or impersonation. The adversary’s general strategy is to disguise a malicious face image by altering it on the pixel level in the hope that it will be accepted by the FRS. Assuming the target FRS is based on a well-designed DNN that is transparent to the adversary (white box). The adversary can directly formulate an optimization problem which outputs a best disguise for any input image. And of course dodging and impersonation will have different target functions based on their objectives. Here are a dodging attack and a impersonation attack against a transfer-learned DNN FRS in [4]:

Figure 2. A dodging attack by perturbing an entire face. Left: a face image of Julia Jones. Middle: image after perturbation. Right: pixels perturbed.

Figure 3. An impersonation attack with eyeglass frames. Left: a face image of Kaylee Defer. Middle: image after adding a frame. Right: Nancy Travis, the impersonation target.
As you can see in Figure 2 and Figure 3, altering a small portion of a benign image can mislead the FRS to miss the detection or classify it as another face.
Since the attack is designed to pass adversarial data points through the FRS without altering it, and either dodging or impersonation can be used, this attack can be tagged by “exploratory, integrity, targeted or indiscriminate“.
Example 2: Poisoning Support Vector Machines [1]
Support vector machine (SVM) was the most popular image recognition ML algorithm before the thriving of deep neural networks. Briefly speaking, a typical SVM classifier consists of an optimal subset of its training data set which provides the best separating hyperplane for the training data.
In this example, rather than merely evading classification, the adversary schemes to alter the SVM classifier itself by chronically feeding it carefully designed training data points. After adequate rounds of feeding, the target SVM will become poisoned so deeply that it will produce false negatives with high probability and eventually be abandoned by its users.
Figure 4 shows a specific example how the adversary generates a optimal poisoning training data point for a single iteration. The adversary first chooses a support vector from the attacked class (red), re-labels it as the attacking class (blue), then performs gradient ascent to relocate it to a local maximum with respect to a certain classification error measure.
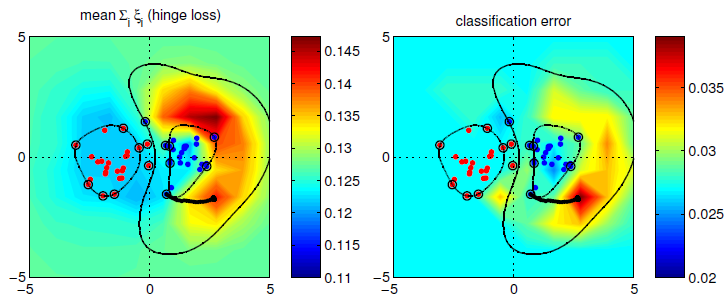
Figure 4. Behavior of the gradient-based attack on the Gaussian data sets for the SVM with RBF kernel. Red: the attacking class. Blue: the attacked class.
Figure 5 shows the result after many iterations of the above poisoning operation. The error rate of the SVM classification increases with more iterations of poisoning. As you may know that a 25% error rate is high enough for MNIST data set to declare the classification system fails.
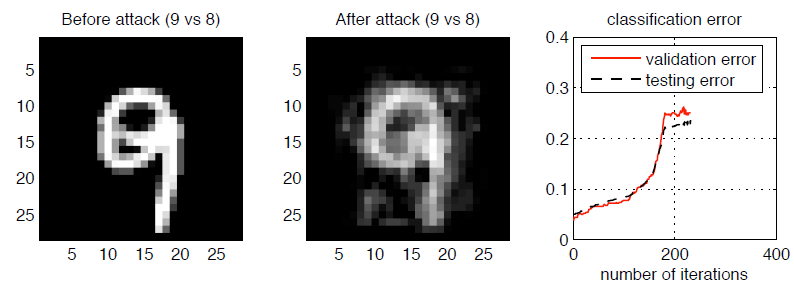
Figure 5 (a). Modifications to the initial (mislabeled) attack point
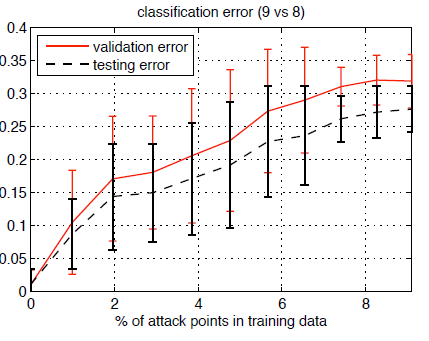
Figure 5 (b). Attack performance increases with percentage of attack points
Since the attack causes degradation of the machine learning model, affects the classification accuracy and system usability, and target the training data set as a whole, thus this attack can be tagged as “causative, integrity and availability, indiscriminate“.
Example 3: Membership Inference [5]
For some supervised learning tasks, it is essential to keep the training data set secret. A well known example is the clinical study of genetic disease, where patients’ gene data records are used for building a statistical model. And any patient’s gene data should be kept secret. In this scenario, the adversary’s goal is to infer whether a certain data record was used for training the ML model.
Different from the previous two examples, the adversary in this example treats the machine learning system as an oracle and have no knowledge on its internal mechanisms. In other words, the attack is “black-box”. Figure 6 provides a conceptual attack model:
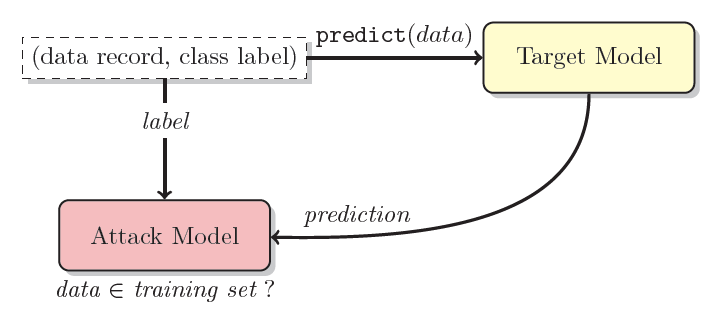
Figure 6 (a). Black-box membership inference attack model.
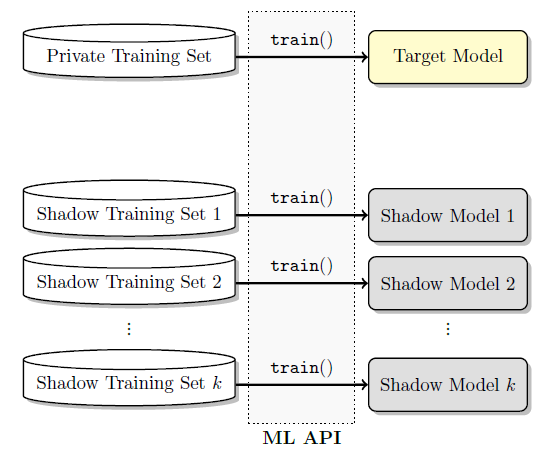
Figure 6 (b). Training a bank of shadow models that approximate the target model.
To evaluate the attack proposed in [5], the author tested it against a purchased data set trained on a targeted Google’s ML model. Figure 7 presents the attack result and a explanatory illustration on why this attack works.
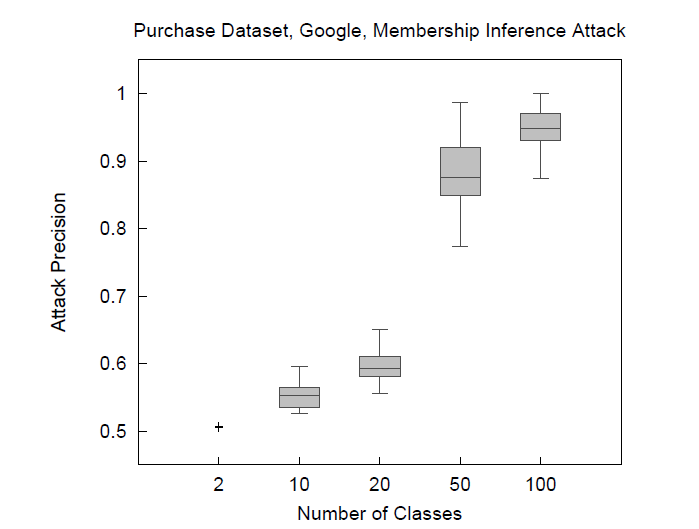
Figure 7(a). Attack precision.
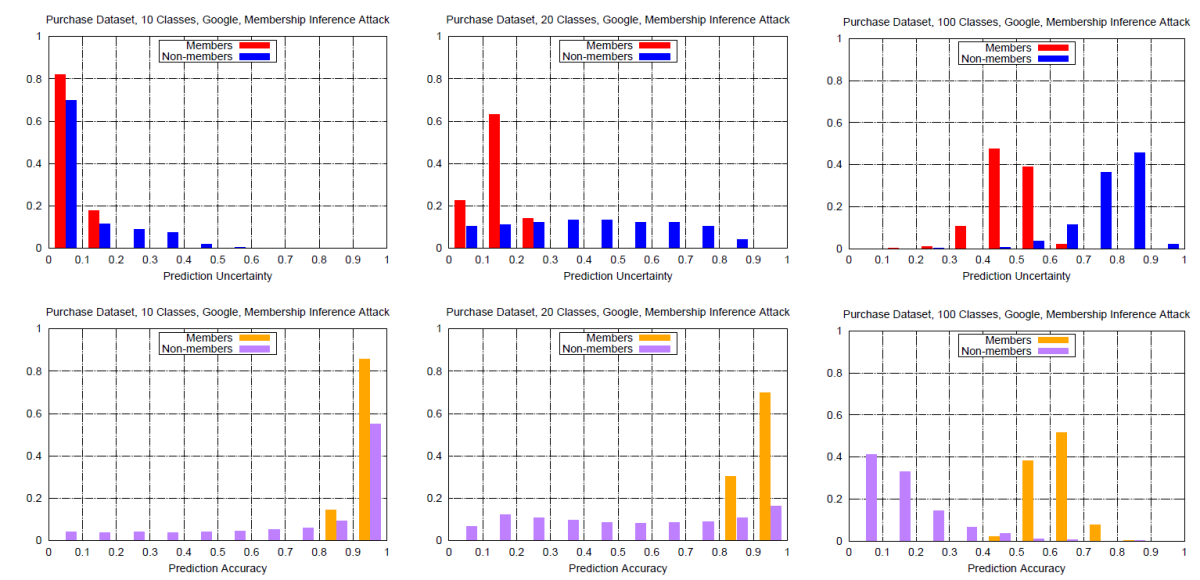
Figure 7(b). Performance of the targeted model which can explain why the attack works well when there are more classes.
As you can see from Figure 7, when there are more classes, the discrepancy of histograms for targeted model’s prediction accuracy (uncertainty) between members and non-members is bigger, of which can be taken advantage by the adversarial performing the proposed attack.
Since the adversary’s goal is to breach the identities of certain training data points and have no intention to alter the targeting system, this attack can be tagged “exploratory, privacy, targeted“.
Exploring Countermeasures
It is generally difficult to form an automatic defense strategy against attacks against machine learning and it is also an active research area. The general idea is to increase attackers’ cost and delay the time of breach. Here gives a non-exhaustive list of possible defense methods:
Robust features. Discarding trivial and non-representative features while adding more distinct and robust features.
Combined models. Using several different classifiers sequentially or in a more complex manner in the hope to aggregate edges of different models.
Randomization. Randomizing or altering the classification output to mislead the attacker while acquiring knowledge of the ML system.
Adversarial retraining. Actively retraining the ML model on possible adversarial data points.
Manual intervention. Hiring a human observer to manually detect anomalies and malicious sources.
Although we have quite a few defense tools as above mentioned, it is important to know that the adversarial may as well adapt and develop new attacking strategies. Hence an “arm race” is a proper analogy for the feud between between the adversary and the targeted ML system.
End Notes
Perhaps you will never come to the case of building ML algorithms for classifying mutants for Prof. Xavier, nonetheless building a real-world machine learning system that is robust in adversarial settings is no less challenging. The research of adversarial machine learning still has a long way to go.
References
[1] Biggio, Battista, Blaine Nelson, and Pavel Laskov. "Poisoning attacks against support vector machines." arXiv preprint arXiv:1206.6389 (2012). Link [2] Dalvi, Nilesh, et al. "Adversarial classification." Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004. Link [3] Huang, Ling, et al. "Adversarial machine learning." Proceedings of the 4th ACM workshop on Security and artificial intelligence. ACM, 2011. Link [4] Sharif, Mahmood, et al. "Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition." Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016. Link [5] Shokri, Reza, et al. "Membership inference attacks against machine learning models." Security and Privacy (SP), 2017 IEEE Symposium on. IEEE, 2017. Link [6] Tygar, J. D. "Adversarial machine learning." IEEE Internet Computing 15.5 (2011): 4-6. Link [7] Wikipedia - Adversarial machine learning. Link [8] Xu, Weilin, Yanjun Qi, and David Evans. "Automatically evading classifiers." Proceedings of the 2016 Network and Distributed Systems Symposium. 2016. Link